
# Bag-of-Words
- 딥러닝 기술이 적용되기 이전에 많이 활용되던 단어 및 문서를 숫자 형태로 나타내는 가장 간단한 기법
- 단어들의 순서는 고려하지 않고 단어들의 출현 빈도에만 집중하는 텍스트 데이터의 수치화 표현 방법
- Step1. Constructing the vocabulary containing unique words
- 사전(vocabulary) 형태로 저장할 때 단어들의 중복 허용X
- "John really really loves this movie", " Jane really likes this song"
=> {"John", "really", "loves", "this", "movie", "Jane", "likes", "song"}
- Step2. Encoding unique words to one-hot vectors
- 각각의 단어를 categorical variable(범주형 변수)로 볼 수 있음
- categorical variable을 one-hot-vector로 표현
- 어떤 단어쌍이든 유클리드 거리는 √2
- 어떤 단어쌍이든 코사인 유사도는 0

- 문장/문서는 word 레벨의 one-hot-vector를 확장해서 나타낼 수 있음
=> 문장이나 문서들에 포함된 단어들의 one-hot-vector들을 모두 더한 벡터로 나타냄
=> Bag-of-Words

# Naive Bayes Classifier
- BoW를 활용한 대표적인 문서 분류 기법
- BoW로 나타낸 문서를 정해진 클래스/카테고리 중 하나로 분류
- 인공 신경망 알고리즘에는 속하지 않지만 머신러닝의 주요 알고리즘으로 분류에 있어 준수한 성능을 보여줌
- 총 C개의 클래스가 있는 경우

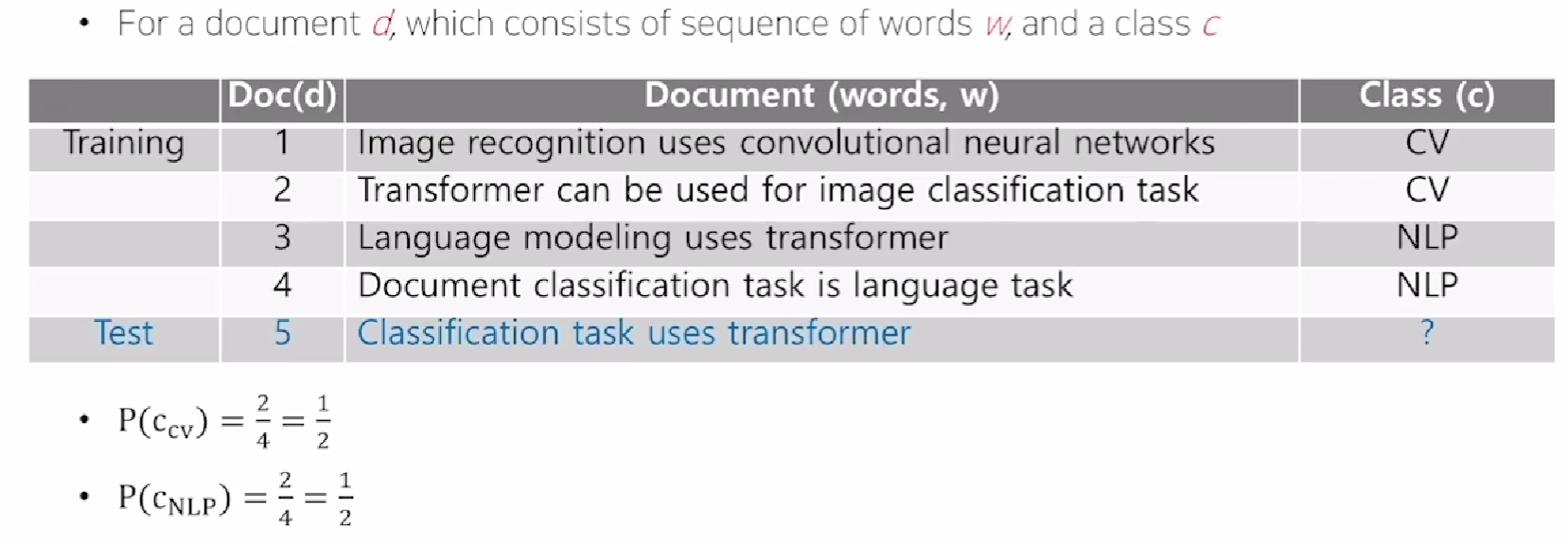


- 단점
- 다른 단어들이 분류하고자 한느 문장에 많이 등장했을지라도 Training data에서 한 번이라도 등장하지 않은 단어가 문장에 있다면 모든 단어들의 확률 곱으로 인해 0으로 수렴하게 됨
=> 분류를 제대로 하지 못하게 됨
- 다른 단어들이 분류하고자 한느 문장에 많이 등장했을지라도 Training data에서 한 번이라도 등장하지 않은 단어가 문장에 있다면 모든 단어들의 확률 곱으로 인해 0으로 수렴하게 됨
# 참고글
https://www.boostcourse.org/ai330/lecture/1455361?isDesc=false
자연어 처리의 모든 것
부스트코스 무료 강의
www.boostcourse.org
'딥러닝' 카테고리의 다른 글
| [개념] RNN, 시퀀스-투-시퀀스 (0) | 2023.02.09 |
|---|---|
| [개념] Word Embedding, Word2Vec, GloVe (0) | 2023.02.09 |
| [개념] 딥러닝 학습 방법 이해하기 (0) | 2023.01.31 |
| [개념] 한국어 전처리 패키지(Text Preprocessing Tools for Korean Text) (0) | 2023.01.25 |
| [개념] 어간 추출(Stemming) 및 표제어 추출(Lemmatization) (0) | 2023.01.22 |